
[#12] Deep Dive into Clustering (Part 2)
k-Means and HDBSCAN: a detailed comparison


In my previous blog post and Jupyter notebook, I look at k-Means clustering, and, in particular, how to determine the number of clusters in an automated way. For more background on the k-Means algorithm, which is perhaps the best-known unsupervised learning algorithm, check out this video from Coursera.
One of the benefits of the k-Means algorithm is that it is fast, faster than most other clustering algorithms.
This speed is great if you have a large dataset, and you know a priori how many clusters there are in the data. In many cases, we do not know this, and unless the data is only two-dimensional (i.e., only two features), then it is difficult to visualize the data in a way that we can easily verify visually the number of clusters.
Perhaps, even more importantly, what if we know the number of clusters, but the k-Means algorithm clusters the data incorrectly?
In the previous post, I used three or four normally-distributed blobs of points. But, in a more realistic case, what if the clusters have different shapes and the input data are not distributed in a neatly Gaussian way?
An alternative to k-Means clustering is a family of algorithms known as density-based clustering algorithms. One example is DBSCAN, where you define some density that the clusters should have. The algorithm starts at one point and continues adding to the cluster as long as the density meets the threshold set.
So, in this case, instead of having to figure out the number of clusters, one must figure out some reasonable density for the clusters in your dataset, which also is not necessarily always straightforward. You could also have different clusters with different densities.
A relatively recent algorithm that addresses this is HDBSCAN. There is a great lecture and also this article that describe HDBSCAN and how it works. One does not have to set the density for the algorithm to work, and it attempts to determine the optimal clustering on its own.
And, luckily for those of us who are Python users, there is a Python implementation that is fast.
In this post, I will explore how HDBSCAN performs on a variety of datasets (I simulate 6 different data sets here, including the 3 from the previous post), and see if it gives an optimal clustering, quickly, without having to do too much adjusting of the model parameters.
You can find a Jupyter notebook with all of the code needed to generate the results below on GitHub.
Sample Data
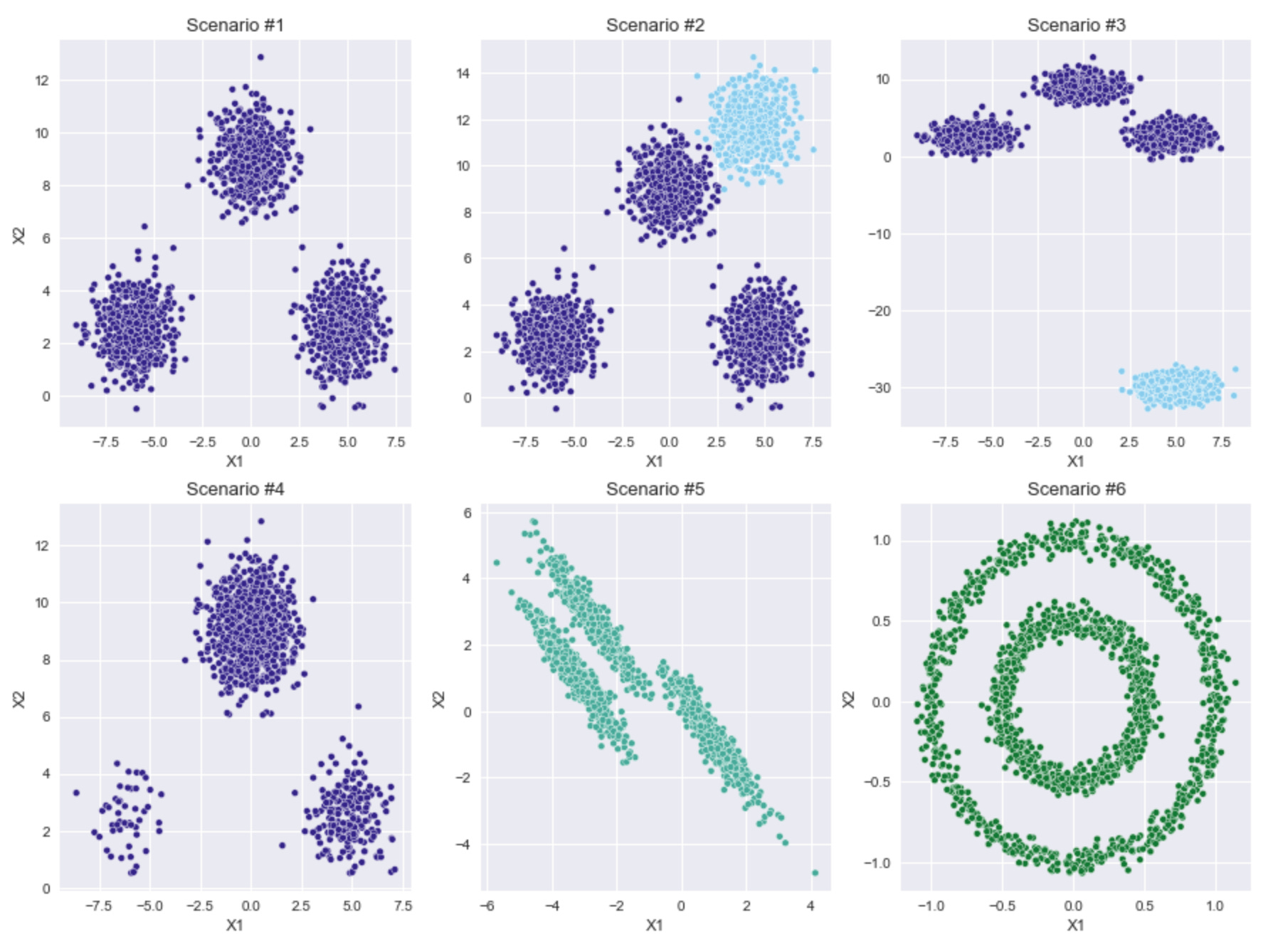
For this demonstration, I again use the three datasets from the previous post, as well as three more datasets, all using scikit-learn functions for creating simulated data.
I designed the sample data so that visually it should be fairly obvious how many clusters there are, and then we can see how k-Means and HDBSCAN handles each one below.
As reminder, the three datasets from the previous post are:
Three simple, well-separated blobs.
The same three blobs from scenario #1, plus an additional blob very close to one of the existing ones (but all 4 are still visually separable).
The same three blobs from scenario #1, plus a fourth blob very far away.
And here are 3 more scenarios:
The three blobs from above, but with different densities.
Three blobs that are stretched to be much more of an oval shape.
Two concentric circular blobs.
How does k-Means Perform on the New Datasets?

In the plots above, I show again the best clustering found for the first three scenarios from the previous post.
For the three new scenarios, I run the same function from the previous post for finding the best number of clusters and use the optimal cluster number based on the silhouette coefficient.
Where k-Means Breaks Down
One problem with k-Means is that it will force a clustering, even if it doesn't make sense.
This is evident in Scenarios #5 and #6 above, where the clusters are not blobs with normally distributed data.
For Scenario #5, with the 3 elongated blobs, the silhouette coefficient indicates that 2 clusters is the right number, and the prediction strength indicates 6 clusters.
For Scenario #6, with the concentric circular clusters, the silhouette coefficient indicates that 10 clusters is the right number, while the prediction strength indicates there is just 1 cluster.
By eye, it looks like there are 3 clusters in Scenario #5 and 2 clusters in Scenario #6. What if we chose those cluster numbers and re-run k-Means?

Clearly, this is problematic if we set-up an automated clustering routine that uses one of the above methods for finding the ideal number of clusters, and just going with that.
Maybe a different algorithm can help here.
HDBSCAN: Can it Automatically Find the Right Number of Clusters?
First, I want to see what happens if I just run HDBSCAN on all six scenarios, using the default parameters.
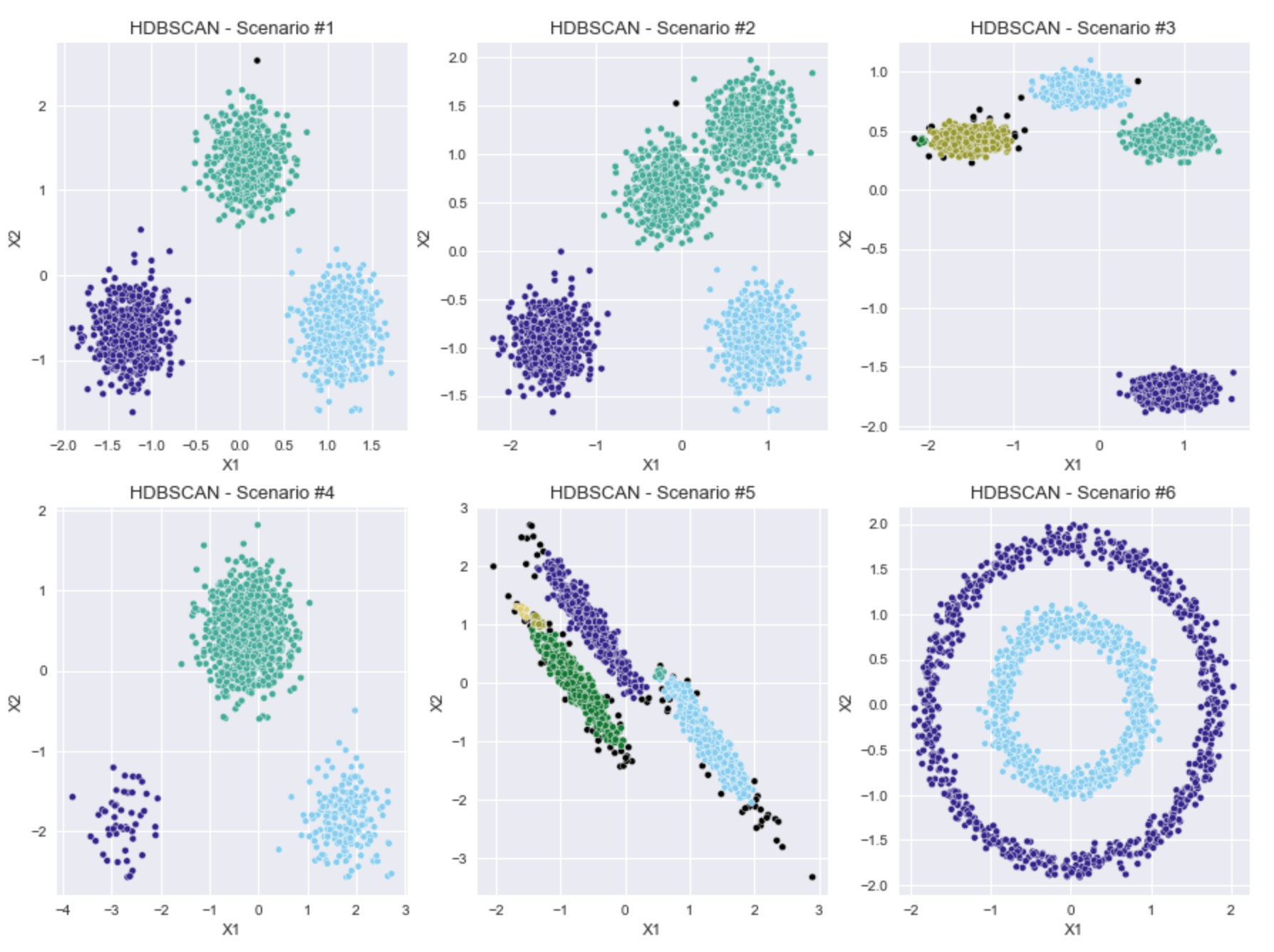
The results in the plots above aren't too bad, considering that I made no manual adjustments to the default parameters for the HDBSCAN model.
It seems here that HDBSCAN can handle a variety of shapes, from the normally distributed blobs to the concentric circular clusters.
The one scenario where it appears to really have broken down is Scenario #2, where the two blobs that are very close together were merged into one cluster. Also, in Scenarios #3 and #5, a couple, very small clusters were added, where I was not expecting to see additional clusters.
Adjusting HDBSCAN Parameters
There a few parameters for HDBSCAN that can be adjusted:
I will try adjusting just min_cluster_size and min_samples and see how the results look.
In order to do this in an automated way, I wrote a function that runs HDBSCAN with different pairs of values for these two parameters. In order to determine the best pair of parameters, I investigate using the silhouette coefficient, as well as a metric that is used for density-based clustering algorithms called Density Based Cluster Validity (DBCV). Essentially, the DBCV compares the density within clusters to the density between the clusters. A good clustering result should have high densities within clusters, and lower densities in between.
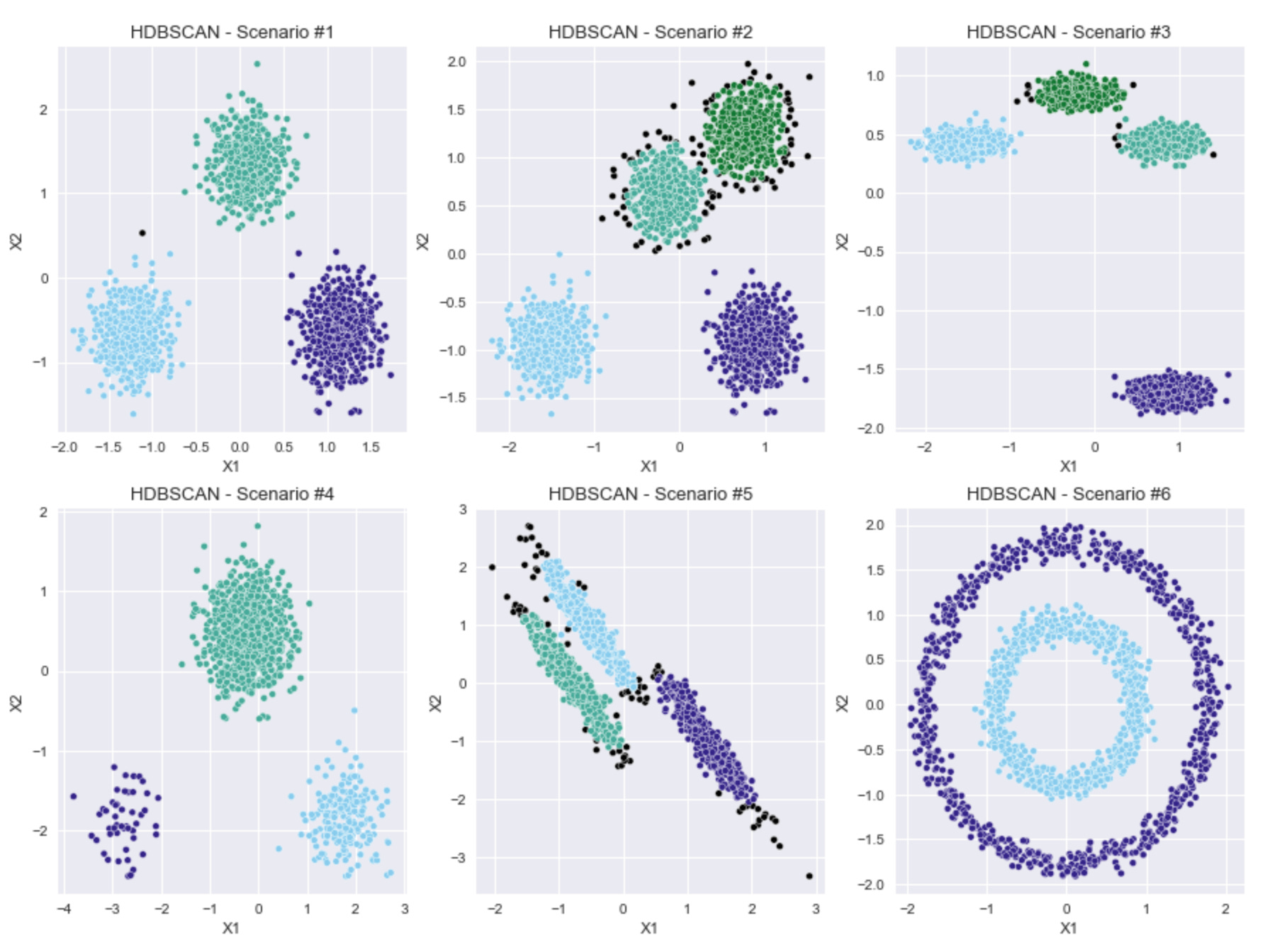
Looking at the results above, using the silhouette coefficient seems to give good results. The numbers of clusters look right, and the algorithm handles the different shapes well.
What about this other metric, the Density Based Cluster Validity (DBCV)?
In some cases, this metric gives similar results as the silhouette coefficient, in terms of comparing how different parameters affect the resulting clustering. However, there are two scenarios above where I think the silhouette coefficient gives better results.
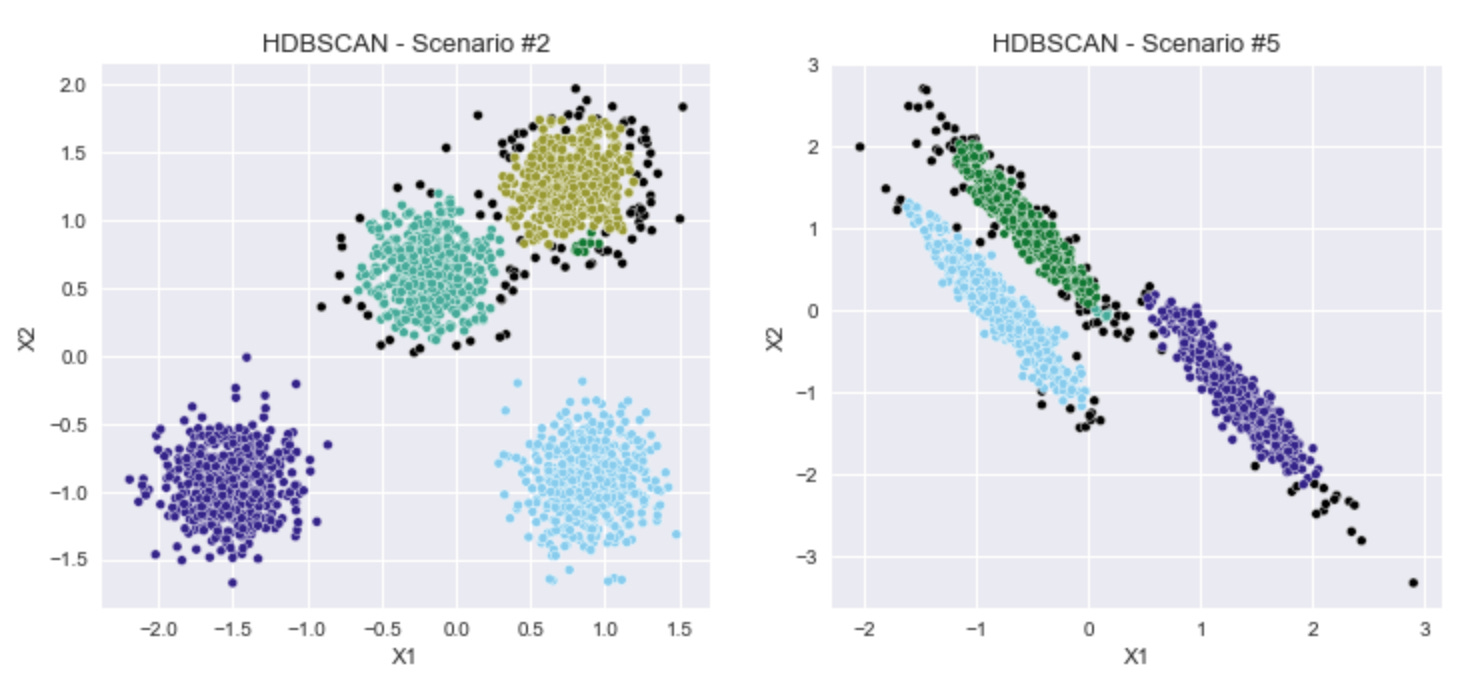
In Scenario #2, where I generated four distinct blobs, the run of HDBSCAN that gives the highest DBCV score results in 4 large clusters, which a fifth small cluster.
Similarly, in Scenario #5, an extra small cluster appears (refer to the iPython notebook for the full results).
I visualize these two scenarios here using the model parameters that give the highest DBCV score:
How Long Does it Take to Run Each Technique?
For both k-Means and HDBSCAN, I test how long it takes to run each algorithm 9 times and calculate the silhouette coefficient each time (to find the best parameters for the two models) for Scenario #4.
It took 910 ms to run k-Means the 9 times and 510 ms to run HDBSCAN 9 times. In this case, HDBSCAN was almost twice as fast as k-Means.
Reviewing the Results
In my previous post, I compared different methods for finding the optimal number of clusters when running the k-Means algorithm. In that post, all of the clusters were round, normally distributed blobs of points. In this post, I look at three more datasets, that include different blob shapes, and k-Means does not give good results on these different shapes. The k-Means algorithm will still give a result, and, because we are working in just two dimensions here, we can see visually that the clustering does not look right. But, what about more complex datasets where it is harder to visualize all of the data points?
HDBSCAN performs much better. While running with the default parameters generally works okay for the datasets here, we can get better results by adjusting two of the parameters and optimizing the silhouette coefficient.
It should be noted that with the shapes in Scenarios #5 and #6, the silhouette coefficient value is relatively low, and there may be cases where this metric does not give the best results. However, the Density Based Cluster Validity metric did not perform any better, and in a couple cases, gave sub-optimal results. Perhaps, some combination of these two metrics could be used. It would be worth exploring with more complex datasets, with unusual blob shapes.
The last thing I look at is speed. The k-Means algorithm is popular, in part, because it is fast. However, the Python implementation of HDBSCAN used here is even faster than k-Means, taking 510 ms to run the algorithm 9 times as part of the optimal parameter search, compared to 910 ms for k-Means.
In summary, it appears that HDBSCAN should be your go-to clustering algorithm, but some adjusting of the input parameters may be necessary to get the optimal results.
Just for Fun
If you code in Python and are familiar with PEP 8, then you'll enjoy this song.